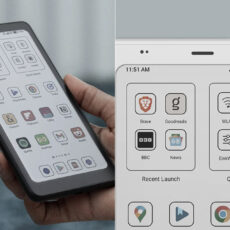
DeepSeek has just released a new tool, DeepSeek OCR, which attempts to extract text from photos of pages while maximizing efficiency. This open-source project from the Hangzhou-based team converts complex papers into something AI can process without running out of memory or power. Developers can download it from GitHub or Hugging Face and integrate it into their applications.
A single NVIDIA A100 GPU can process more than 200,000 pages of data each day. Scale that up to a small cluster (20 servers each with 8 cards), and you’re looking at 33 million pages per day. That’s enough volume to accumulate training sets for larger AI models overnight. DeepSeek created it to satisfy those hungry language models, especially when they have to deal with visual and words.

- 【NEW GENERATION CPU-N95】-- Newest 12th Alder Lake N95 (2.0GHz, MAX TO 3.6GHz, 4 cores, 6MB Cache) processor (2025 New Releases). Compared with...
- 【16GB RAM 512GB SSD UP TO 2TB】-- KAMRUI E2 Mini Desktop Computers is equipped with a high-speed 16GB DDR4, (DDR4 SO-DIMM Slot×1, up to 16GB) to...
- 【UHD Graphics & 4K Dual Screen Display】-- KAMRUI E2 small pc comes with UHD Graphics, Support UHD (4096x2160), 4K@60Hz Dual Screen Display(1*HDMI...
Start with an image of a document, such as a scanned report or a crumpled newspaper layout. DeepEncoder, DeepSeek-OCR’s front end, is launched first. This component contains around 380 million parameters and divides the job into two stages. It employs Meta’s Segment Anything Model, or SAM, which divides the image into logical chunks, such as blocks of text or a single chart in a paragraph. SAM performs close-up work with windowed attention, making it memory efficient even for a full 1,024×1,024 pixel image.

Then comes the squeeze, as a simple two-layer convolutional configuration reduces the visual information by 16. What begins as 4,096 raw patches from the image is reduced to 256 tokens. Those are passed on to a variant of OpenAI’s CLIP model that is optimized for greater scene awareness and global attention. CLIP connects the graphics to language understanding without increasing the compute bill. The end result is a compact bundle of tokens that encapsulates the page.
From there, the decoder takes control. DeepSeek used their own 3-billion-parameter Mixture of Experts model, DeepSeek-3B-MoE, however only 570 million were activated throughout a run: 6 routing experts and 2 shared ones. This selective activation enables it to punch like a full-size model while running as a half-billion parameter lightweight. Feed it the compressed tokens and a prompt, and it will output the text in organized formats, such as Markdown for tables or equations.
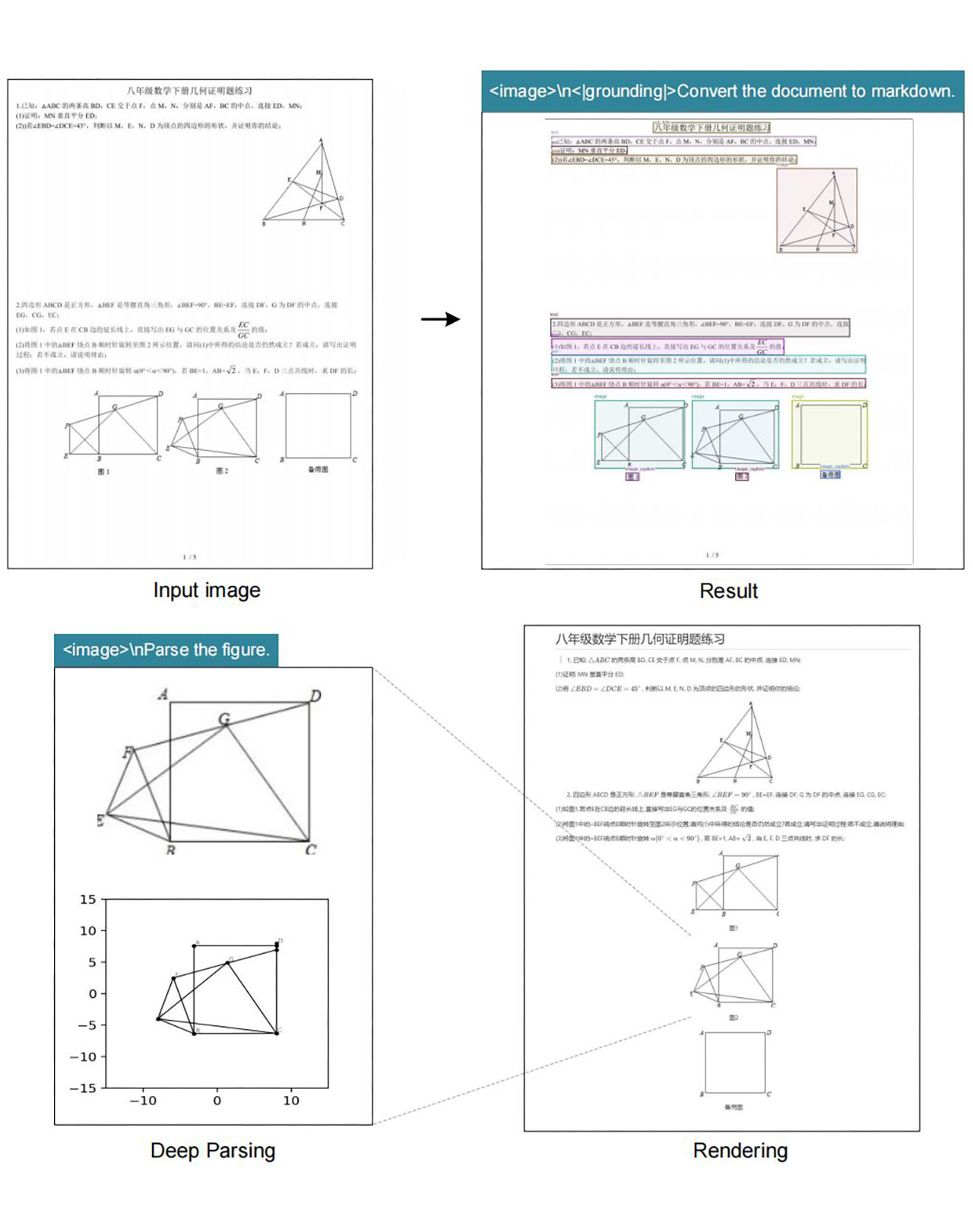
Not every document plays ball in the same way, as DeepSeek-OCR has a few tricks up its sleeve to adapt to whatever chaos it encounters. For the really easy stuff – like slides and memos – it just uses 64 tokens per image and goes easy on the resources. When it comes to books and reports, it ups the ante to around 100 tokens, finding a balance between speed and accuracy.
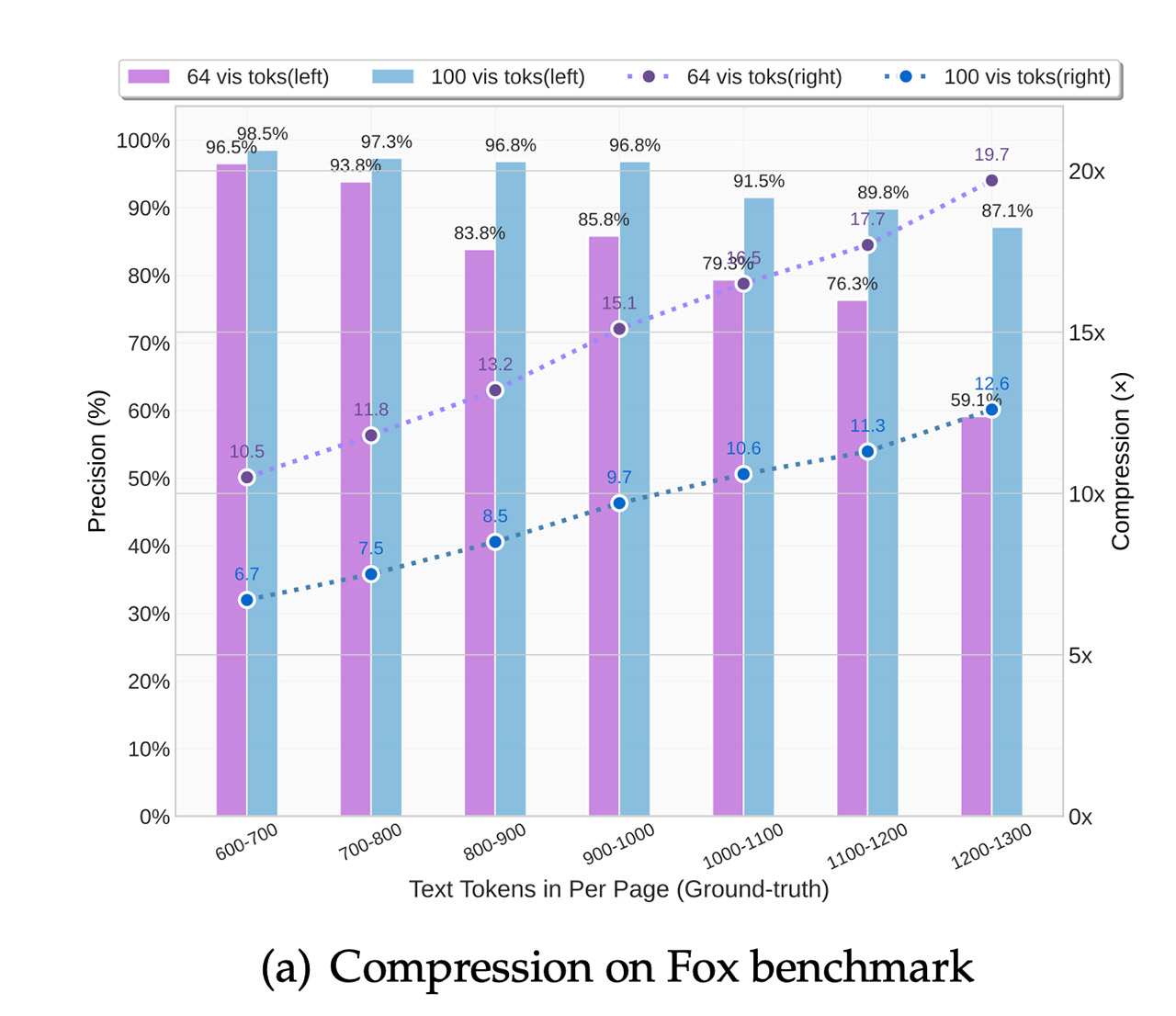
But when the going gets tough, and it’s dealing with newspapers or jam-packed layouts, it breaks out the “Gundam mode” – pretty much maxing out to 800 tokens per image with a sneaky trick of using a sliding window or tiling the image to get a good overview of the whole page.
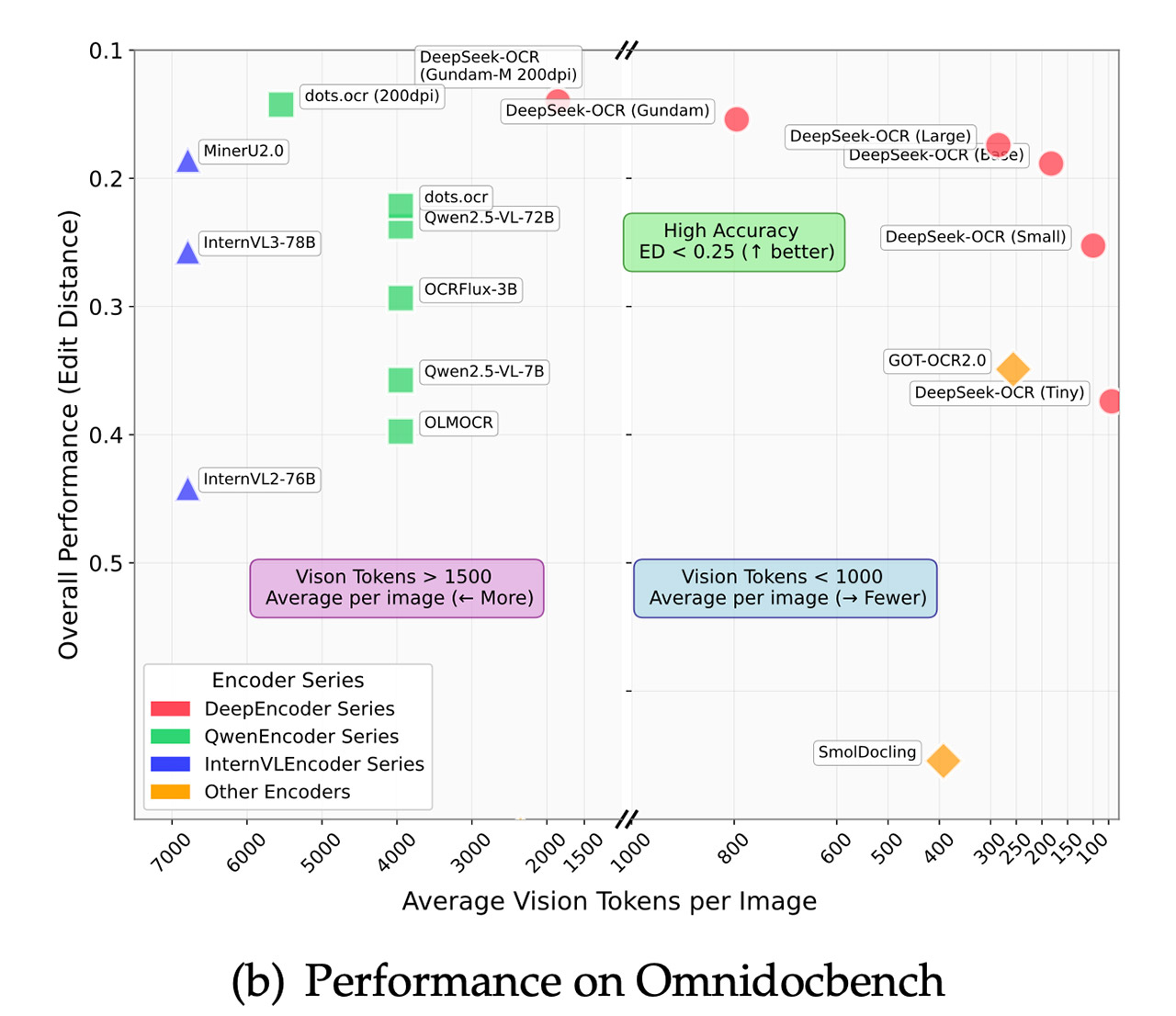
When we put it on the OmniDocBench, which is a benchmark test for how well document parsing software does, DeepSeek-OCR puts on a show. It blows GOT-OCR 2.0 out of the water by using a mere 100 tokens, while its rival is squandering 256. And even when you push it up to 800 tokens, it leaves MinerU 2.0 in the dust, which is chugging along on an average of over 6,000 tokens per page. And to top it all off, the edit distances – that’s just a fancy way of saying how many errors it makes – are lower here, especially when it comes to English and Chinese at 200 DPI.