
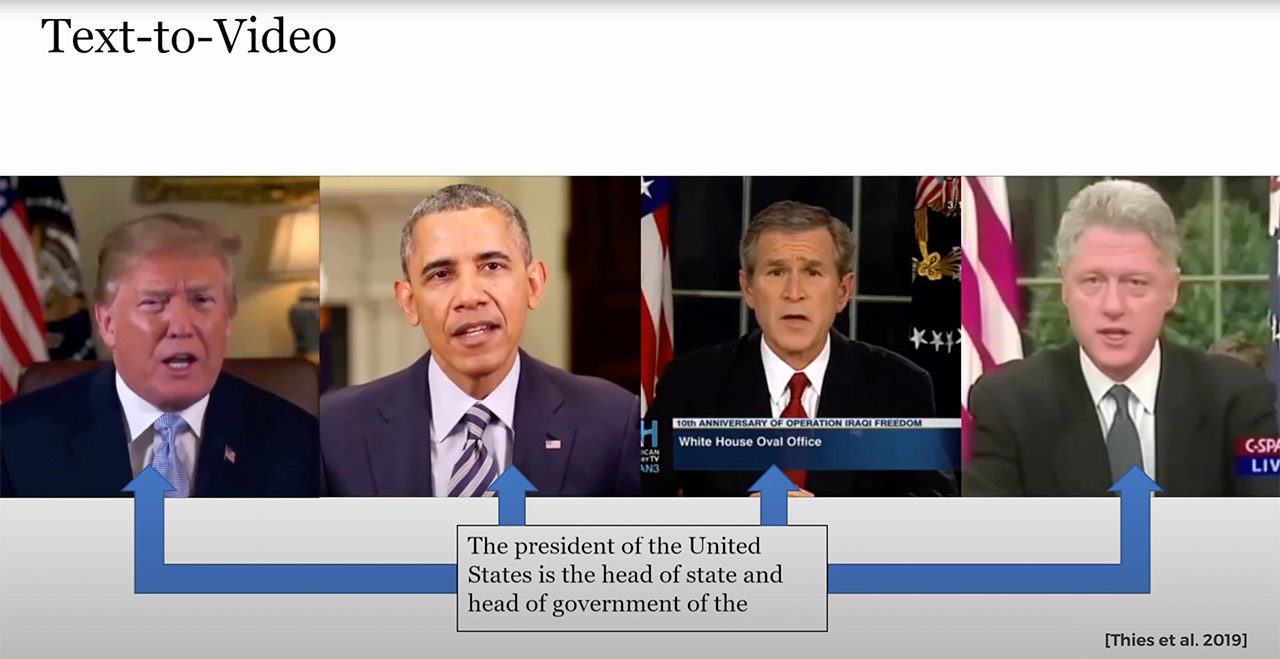
Called Neural Voice Puppetry, artificial intelligence can now make use of audio-driven facial video synthesis, or in other words, create audio deepfakes. When fed an audio sequence of a source person or digital assistant, this system generates a photo-realistic output video of a target person that is in sync with the audio of the source input. This is made possible with a deep neural network that employs a latent 3D face model space.
This approach can be generalized across different people, allowing one to synthesize videos of a target actor with the voice of any unknown source actor or even synthetic voices that can be generated utilizing standard text-to-speech approaches. In the real world, it can be used for video avatars, video dubbing, and text-driven video synthesis of a talking head.

- BEATS' CUSTOM ACOUSTIC PLATFORM delivers rich, immersive sound whether you’re listening to music or taking calls.
- LOSSLESS AUDIO via USB-C plus three distinct built-in sound profiles to enhance your listening experience
- HEAR WHAT YOU WANT with two distinct listening modes: fully-adaptive Active Noise Cancelling (ANC) and Transparency mode


