
Google DeepMind’s Gemini Robotics 1.5 models are a huge step toward robots that think, plan, and act intelligently, potentially changing how machines interact with our world.
Gemini Robotics 1.5 is available in two versions: a vision-language-action model and an embodied reasoning model known as Gemini Robotics-ER 1.5. They form a dynamic duo that enables robots to complete difficult, multi-step tasks. The vision-language-action technique converts what the robot sees – a mound of laundry or a cluttered workstation – into exact movements. The hands interpret commands such as “take up the red jumper” into actual arm movements. Meanwhile, the brain serves as the embodied reasoning model, making high-level decisions, planning sequences, and even conducting online contextual searches. If you ask a robot to separate trash, compost, and recycling, this model consults local guidelines, decides what goes where, and instructs the vision-language-action model on how to complete each step.

- Google Pixel 9a is engineered by Google with more than you expect, for less than you think; like Gemini, your built-in AI assistant[1], the incredible...
- Take amazing photos and videos with the Pixel Camera, and make them better than you can imagine with Google AI; get great group photos with Add Me and...
- Google Pixel’s Adaptive Battery can last over 30 hours[2]; turn on Extreme Battery Saver and it can last up to 100 hours, so your phone has power...
When faced with a task such as sorting laundry by color, the robot does not just grab clothes. The embodied thinking paradigm divides down the aim into two bins: white garments in one and everything else in the other. It then devises a strategy: find a red sweater and place it in the appropriate bin. The vision-language-action model takes over, calculating the precise movements required to pick up and arrange the sweater in the correct location. This layered technique of thinking before doing enables the robot to perform tasks that involve both brains and brawn, such as cleaning a room or organizing a workshop.
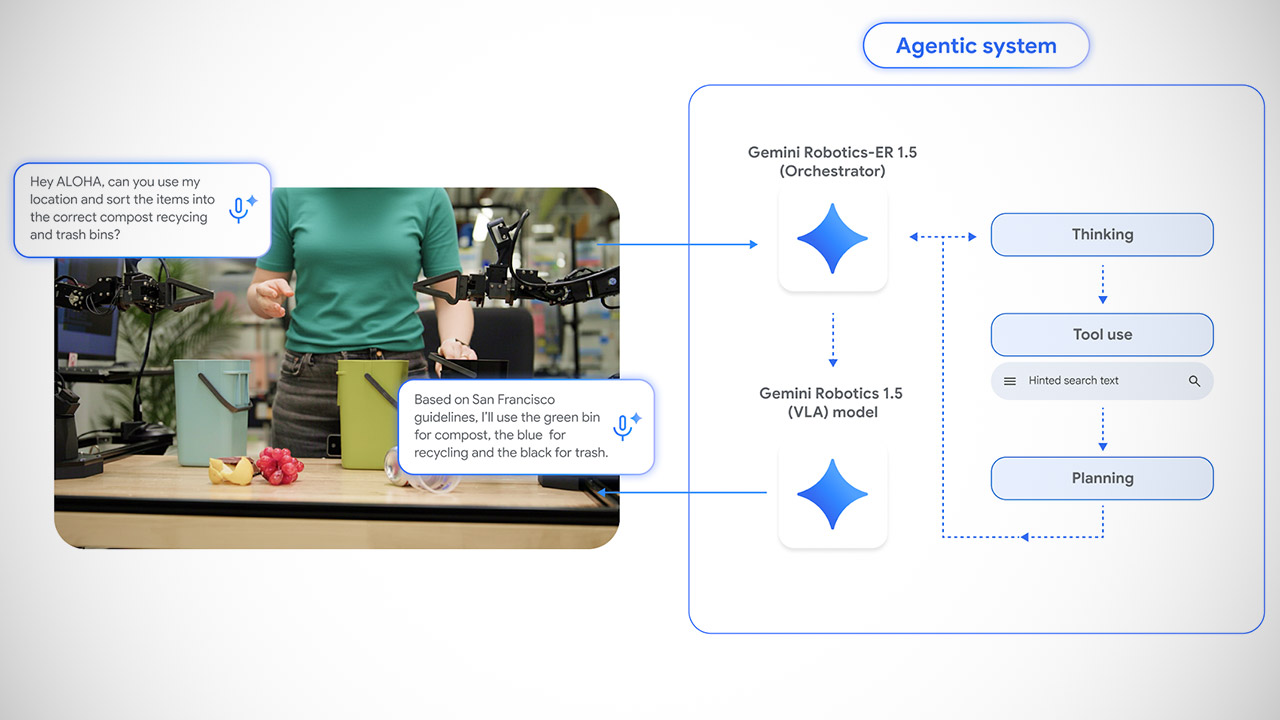
Another significant advance is the way these models adapt to various robot bodies. Robots exist in different shapes and sizes, including humanoid, multi-armed, and wheeled vehicles. Previously, teaching one robot a task did not help another with different hardware. Gemini Robotics 1.5 turns this on its head. Skills acquired on a two-armed ALOHA 2 robot can be transferred to a humanoid Apollo or a bi-arm Franka robot without having to start over.
The embodied reasoning model thinks before acting, so the robot will not, for example, knock over a glass while reaching for a spoon. It also matches with Google’s overarching AI safety policies, ensuring pleasant and safe interactions. On the hardware side, low-level systems such as collision avoidance kick in as needed. Google’s ASIMOV benchmark tests a variety of safety aspects, including semantic understanding and physical restrictions.
Developers can already access Gemini Robotics-ER 1.5 via the Google AI Studio API and select partners can use the vision-language-action model. This is a glimpse into a future where robots will be as common as cellphones, doing everything from recycling to furniture assembly.







