
Here’s a first look at NVIDIA Fugatto (Foundational Generative Audio Transformer Opus 1), a new generative AI model that can generate audio output simply using text. This model not only understands audio, but it generates sound like humans would.
What really sets Fugatto apart from other text-to-audio generators is the model’s ComposableART technique, which combines instructions that were only seen separately during training. An example would be using a combination of prompts asking for text spoken with a sad feeling in a French accent, and due to the model’s ability to interpolate between instructions, it would give users fine-grained control over things like the heaviness of the accent or the degree of sorrow.

- POWER UP YOUR PLAY - Win more games with Windows 11, a 13th Gen Intel Core i7-13650HX processor, and an NVIDIA GeForce RTX 4060 Laptop GPU at 140W Max...
- BLAZING FAST MEMORY AND STORAGE – Multitask swiftly with 16GB of DDR5-4800MHz memory and 1TB of PCIe Gen4 SSD.
- ROG INTELLIGENT COOLING – The Strix G16 features Thermal Grizzly’s Conductonaut Extreme liquid metal on the CPU, and a third intake fan among...
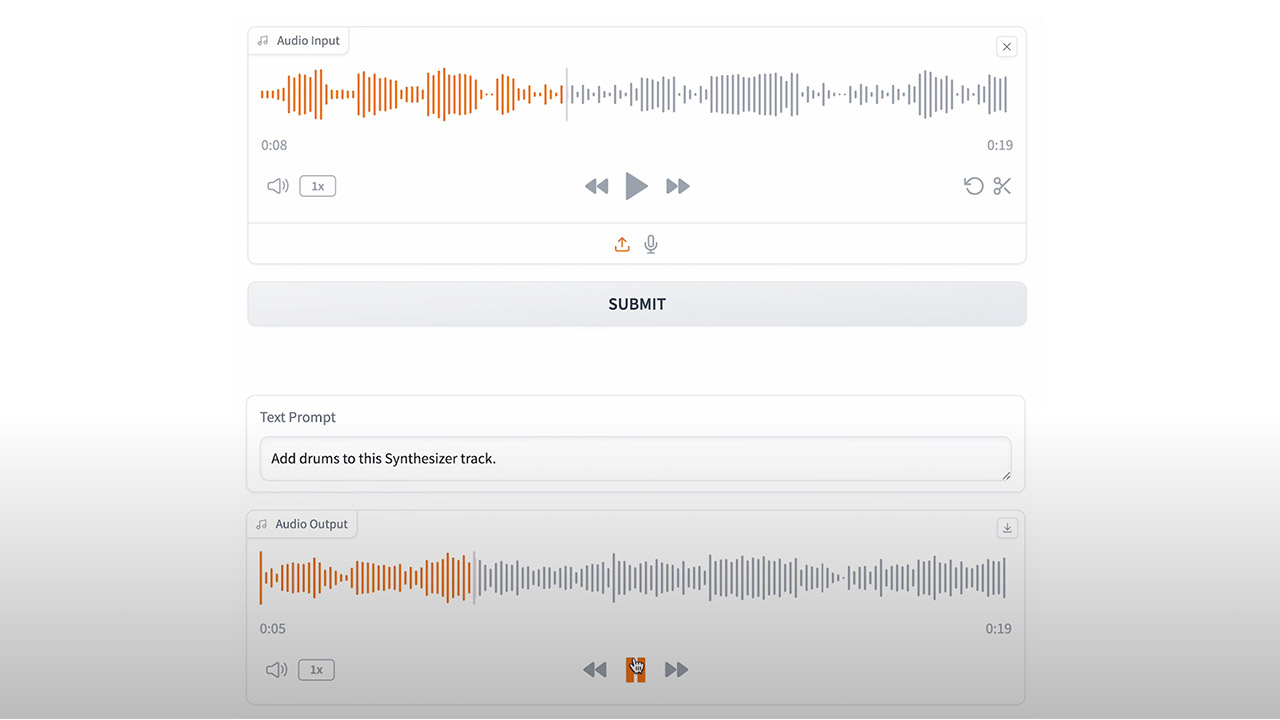
This thing is wild. Sound is my inspiration. It’s what moves me to create music. The idea that I can create entirely new sounds on the fly in the studio is incredible,” said Ido Zmishlany, Co-Founder of One Take Audio and Member of the NVIDIA Inception Program.







