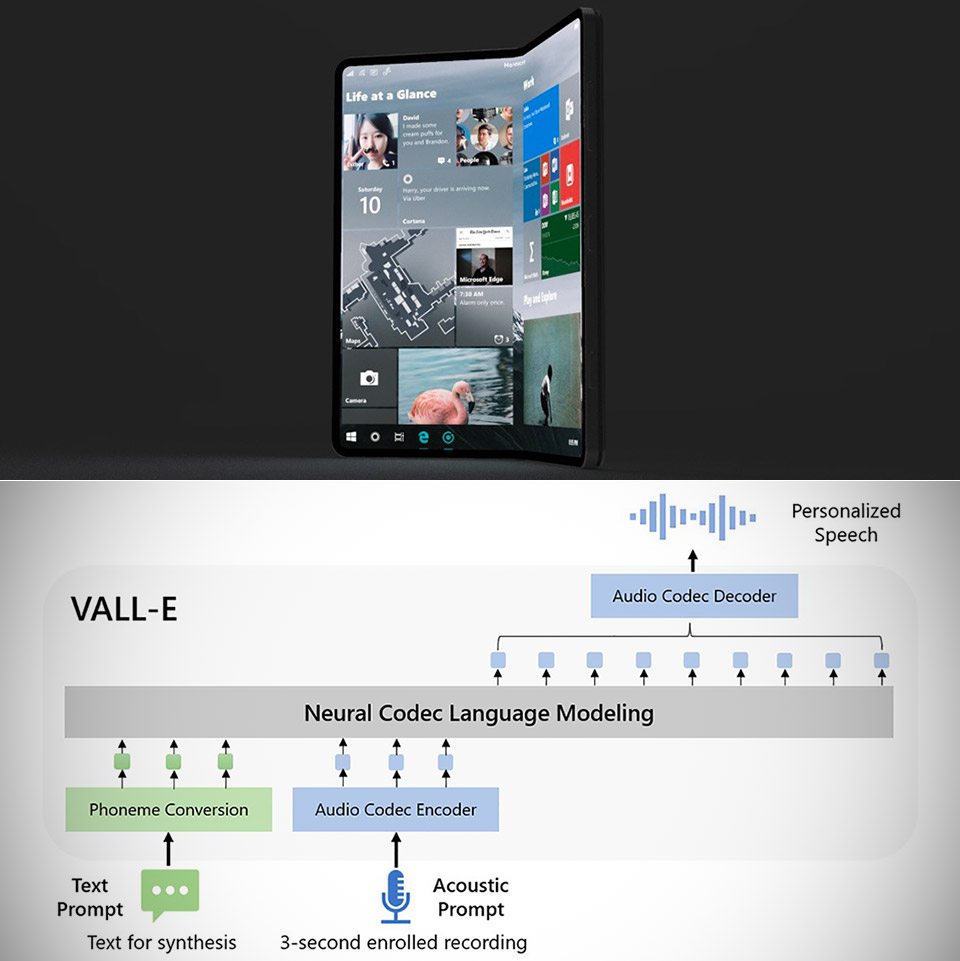
You won’t need this Mac Mini-like Windows Dev Kit to run Microsoft’s VALL-E speech synthesis AI, just any modern PC. This new speech synthesis AI model is capable of recreating your voice using just 3-seconds of audio including the tone, charisma, and more. It’s based on EnCodec, a neural codec language model that generates discrete audio codec codes from text and acoustic prompts.
What is a neural codec language model? It basically means that VALL-E breaks how a person sounds into individual components, called tokens, and then uses training data to simulate what that voice would sound like outside of the provided audio sample. So far, they’ve trained it on over 60,000 hours of the English language from more than 7,000 speakers. Check out more More demos here now.

- Introducing Copilot on Windows 11, your everyday AI companion - Copilot empowers you to create faster, complete tasks with ease and lessens your...
- Immersive 13" touchscreen – Adapts to your surroundings, adjusting the color balance to best suit your environment.
- Hinges on your every move – Adjust the angle with built-in Kickstand, adding Surface Pro Signature Keyboard[1] for instant laptop productivity.
We introduced VALL-E, a language model approach for TTS with audio codec codes as intermediate representations. We pre-train VALL-E with 60K hours of speech data, and show the in-context learning capability in zero-shot scenarios. We achieve new state-of-the-art zero-shot TTS results on LibriSpeech and VCTK. Furthermore, VALL-E could keep the acoustic environment and speaker’s emotion in synthesis, and provide diverse outputs in different sampling-based decoding processes,” said the researchers.




